
GPT-5.1がリリースされたのは、ついこの間の11月。しかし「温かみがあるけど仕事ができない」と酷評され、直後に登場したGoogleのGemini 3に完敗してしまいました。
そこからわずか数週間。OpenAI社内で「コードレッド(非常事態宣言)」が発令され、サム・アルトマンCEOの号令のもと突貫工事で開発されたのが、今回のGPT-5.2です。
「温かみ」から「冷徹な業務マシーン」へ
GPT-5.1のキャッチフレーズは「Warmth(温かみ)」と「Personality(個性)」でした。会話は楽しく人間味があったものの、肝心の論理的推論やコーディング能力でGemini 3に惨敗したのです。
対して、GPT-5.2のキャッチコピーは明確です。
「プロフェッショナルワークと、長時間稼働エージェントのための、最先端フロンティアモデル」
今回、OpenAIはなりふり構わず「経済的価値」を前面に押し出してきました。
驚異的な生産性向上
OpenAIのデータによると:
- ChatGPT Enterpriseの平均的ユーザーは1日40〜60分の時間を節約
- ヘビーユーザーは週10時間以上を節約
- GPT-5.2はこの「節約時間」をさらに増やすために設計された
単に質問に答えるだけではありません。複雑で多段階のプロジェクトを完遂できるのです。
たとえば「来月の売上予測をして」と依頼すると:
- 過去のデータを自動分析
- 市場トレンドを検索
- Excelファイルを作成
- パワーポイントに貼り付け
- メールの下書きまで作成
全てを自律的に処理します。
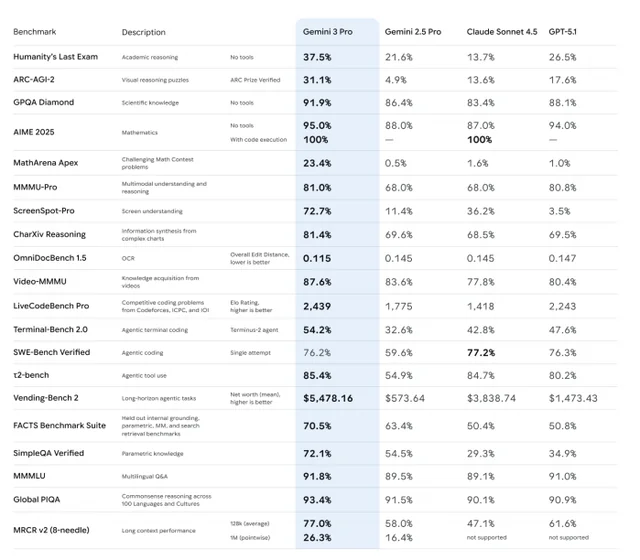
衝撃のベンチマーク結果
OpenAIが発表したベンチマーク結果は、話半分で聞いても「異常」なレベルです。
GDPval(知識労働タスク)
- GPT-5.1: 38.8%
- GPT-5.2: 70.9%
44の職業において、プロフェッショナルと対決して7割以上の確率で勝利または引き分け。人間の専門家と同等か、それ以上のレベルに到達しました。
AIME 2025(競技数学)
- GPT-5.1: 94.0%
- GPT-5.2: 100.0%
数学において満点。計算ミスも論理の飛躍もない、完璧な性能です。
SWE-bench Verified(プログラミング)
- GPT-5.1: 76.3%
- GPT-5.2: 80.0%
新人プログラマーどころか、中堅レベルのコーディングタスクをこなします。
ARC-AGI-2(抽象的推論)
- GPT-5.1: 17.6%
- GPT-5.2: 52.9%
これが最も重要です。丸暗記が通用しない「本当の知能」を測るテストで、スコアが3倍に跳ね上がりました。AIが「パターンを覚えている」段階から「未知の問題をその場で考えて解く」段階へ進化した証拠です。
人間より速く、圧倒的に安い
最も恐ろしいのは、このクオリティの成果物を出すのにかかったスピードとコストです。
スピード: 人間の専門家の11倍以上
コスト: 人間の専門家に依頼する場合の1%未満
1万円の仕事が100円以下。人間は「遅くて高い」存在になりつつあります。
ある審査員は成果物を見てこうコメントしています。
「これはプロの企業がスタッフを雇って作ったように見える。レイアウトも驚くほどよく設計されている」
3つのモデルバリエーション
GPT-5.2は用途に応じて3つのバージョンが用意されています。
GPT-5.2 Instant
爆速モデル。日常的なメール返信や翻訳に最適。5.1譲りの「親しみやすさ」も残っています。
GPT-5.2 Thinking
今回の主役。複雑な問題を前にすると「考え込んで」から答えを出します。スプレッドシート作成や込み入った計画立案に強い。
GPT-5.2 Pro
上位プランユーザー専用。計算リソースを湯水のように使い、最も深く正確な答えを導き出す「リサーチグレード」の知能。
コーディング能力の飛躍的向上
特筆すべきは、現実世界のソフトウェア開発を評価する「SWE-Bench Pro」で55.6%という新記録を達成した点です。
このテストは:
- 4つのプログラミング言語を扱う
- 「ネットに落ちてる答えをカンニングできない」設計
- 産業レベルに近い難易度
AIが「ただのコピペマシーン」から「悩めるエンジニア」に進化した証拠です。
フロントエンド開発の強化
今回は画面の見た目を作るフロントエンド能力も強化されています。特に3D要素を含む複雑なUIで優れた性能を発揮します。
デモ例:ホリデーカードビルダー
たった一つのHTMLファイルで:
- ドラッグ&ドロップ機能
- 楽しい効果音
- 雪が降るアニメーション
- サンタやトナカイを配置可能
こうした「ふわっとした指示」から完成度の高いWebアプリを生成します。
ハルシネーション(幻覚)は改善されたか?
AI特有の「息をするように嘘をつく」問題は依然として存在します。
OpenAIによると:
- エラー率が8.8%から6.2%に減少
- 30%のエラー削減
ただし、注意すべき点があります:
- この数値は「推論の労力を最大限に設定」した状態
- 検索ツールを有効にした状態
- エラー判定を他のAIが行った
OpenAI自身も「重要な点については、回答を再確認してください」と注意を促しています。
サム・アルトマンの勝利宣言
ここで、サム・アルトマンCEOが米CNBCとのインタビューで放った衝撃の一言を紹介しましょう。
「Gemini 3は、我々が懸念していたほどの影響(インパクト)はなかった」
さらに「来年1月にはコードレッド状態を脱し、非常に強い立場に戻る」と完全勝利宣言。
ついこの間まで顔面蒼白で「緊急事態だ!」と社員を叱咤していたのに、この余裕ぶりです。
企業からの評価
先行利用した企業からは高評価が寄せられています。
Notion、Box、Shopify、Zoom
「最先端の長期的な推論(Long-horizon reasoning)とツール呼び出し性能を示した」
Databricks
「エージェンティックなデータサイエンスにおいて並外れている」
JetBrains
「対話型コーディング、コードレビュー、バグ発見において測定可能な改善が見られた」
まとめ:AI戦争の新局面
GPT-5.2の登場により、GoogleとOpenAIの「最強AI」争いは新たな局面を迎えました。
進化した点:
- 数学・コーディングで満点レベルの性能
- 44職種でプロフェッショナル超え
- 人間の11倍速・コスト1%未満
- 抽象的推論能力が3倍に向上
依然として残る課題:
- ハルシネーション(エラー率6.2%)
- 最終的な確認は人間が必要
- フルパワー設定時の数値という注意点
OpenAIにとって、2025年は激動の年でした。8月のGPT-5は「期待外れ」、11月のGPT-5.1はGemini 3の衝撃にかき消されました。
しかし、コードレッドの突貫工事で投入されたGPT-5.2は、その全てを挽回する性能を見せつけています。
2026年も、GoogleとOpenAIの「意地の張り合い」は続くでしょう。そしてその競争こそが、AI技術の急速な進化を生み出しているのです。
私たちユーザーは、この「殴り合い」の恩恵を受けながら、AIを「優秀な助手」として使いこなしていく時代に突入しました。
ただし、最終責任は人間が持つ――その原則は、GPT-5.2になっても変わりません。






コメント